Usually regularization is applied to regression problems that $X$ is a fat matrix (opposing to tall matrix), $N\times p$ where $p>N$, i.e. you have more predictors than data points.
Then in that case the original Least square solution $(X^TX)^{-1}X^Ty$ doesn't make sense, since $X^TX$ is at most rank $p$ thus degenerate and non-invertible. In the original problem $X\beta = y$ there are more than 1 solution: moving in the null space of $X$ won't change the solution $\beta\in \beta_0+null(X)$.
Then introducing a regularization term e.g. in Ridge, makes the least square formula invertible and unique again
$$
\hat\beta_{ridge} = (X^TX+\lambda I)^{-1}X^Ty
$$
You can argue this brings stability to the solution since adding $\lambda$ reduce the condition number of $(X^TX+\lambda I)$ which makes the inversion more numerically stable.
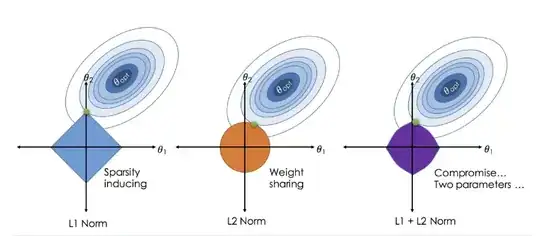
From a geometric viewpoint, we can also say the regularizations added an additional loss term to distinguish the solutions in the solution manifold ($\beta\in \beta_0+null(X)$), which makes the solution unique. (see this famous illustration of the loss landscape of regularized regression)