My cost/loss function drops drastically and approaches 0
When you didn't use any optimizer to optimize the loss as you have said, Technically it's not possible for the cost/loss function to drop drastically and approach zero. It's only because of the optimizer that the model works with the objective of reducing cost/error or in simpler terms from gradient descent hill analogy, optimizer finds"descending the hill in what way accounts for the most reduction in error". Your model just stays at the top of the hill forever!!!. The loss is just a number for your model.

Since there is no optimizer in your code, It's technically not possible that "cost/loss function drops drastically and approaches 0".Your model's loss stays in point B forever
But the weights are still changing in a visible way, a lot faster than the cost function
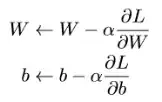
The above given are the update equations. Due to the random prediction of your model, At every batch, Some points tend to get predicted as correct class randomly. This accounts for some very small reduction in loss. And this change in loss is updated on the weights using the equation above. And so you may see random changes in weights for each batch. The overall effect of this change is negligible.
I've also made some real examples with mnist data which I computed without optimizer and the results are as follows:
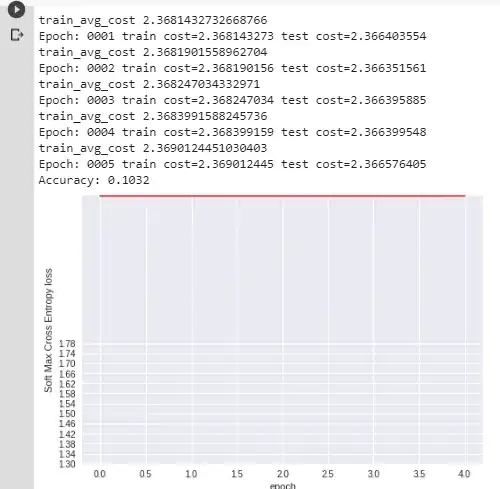
Here you can clearly see the red line(loss) stays on top of the graph forever. I had a batch size of 5 and ran it for 5 epochs



