I'd say the distinct handling of the ordered and unordered factor in decision trees is more convention and
implementation detail than a necessity.
But it is also an important optimization feature. See the documentation of the rpart here
We have said that for a categorical predictor with $m$ levels, all $2^{(m-1)}$ different possible splits are tested..
and
Luckily, for any ordered outcome there is a computational shortcut that allows the program to find the best split using only $m-1$ comparisons.
As you see, the ordered factor may be processed much effectively.
My advice therefore - as a part of the feature ingeneering decide whether to use a factor ordered or unordered:
Use ordered factor only if it is highly correlated with the output variable, otherwise fall back to an unordered factor
Bellow is a simple example, how can a scattered output variable with an ordered factor as a feature fool the decision treee to be very deep and ineffective.
> df
X Y
1 1 0
2 2 1
3 3 0
4 4 1
> str(df)
'data.frame': 4 obs. of 2 variables:
$ X: Ord.factor w/ 4 levels "1"<"2"<"3"<"4": 1 2 3 4
$ Y: num 0 1 0 1
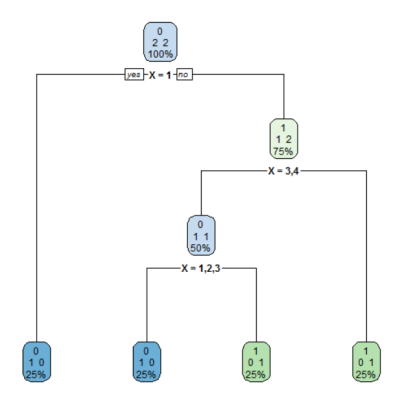
Notice that the output variable $Y$ is highly uncorrelated with the ordered factor.
> fit <- rpart(Y ~ X, method="class", data = df, control=rpart.control(minsplit = 1))
> print(fit)
n= 4
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 4 2 0 (0.50000000 0.50000000)
2) X=1 1 0 0 (1.00000000 0.00000000) *
3) X=2,3,4 3 1 1 (0.33333333 0.66666667)
6) X=3,4 2 1 0 (0.50000000 0.50000000)
12) X=1,2,3 1 0 0 (1.00000000 0.00000000) *
13) X=4 1 0 1 (0.00000000 1.00000000) *
7) X=1,2 1 0 1 (0.00000000 1.00000000) *
Which leads to a deep (and unscalable) decision tree.
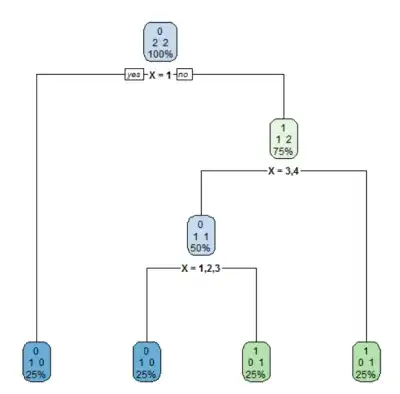
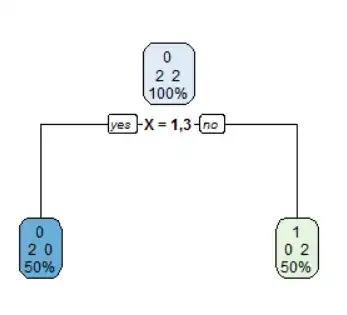
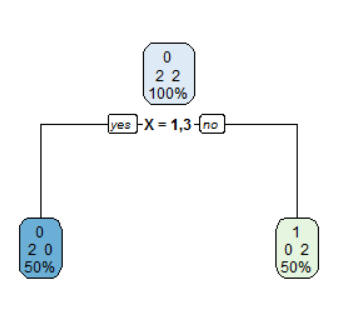
Making the factor unordered results in the optimal decision tree.
> df
X Y
1 1 0
2 2 1
3 3 0
4 4 1
> str(df)
'data.frame': 4 obs. of 2 variables:
$ X: Factor w/ 4 levels "1","2","3","4": 1 2 3 4
$ Y: num 0 1 0 1
>
> fit <- rpart(Y ~ X, method="class", data = df, control=rpart.control(minsplit = 1))
> print(fit)
n= 4
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 4 2 0 (0.50000000 0.50000000)
2) X=1,3 2 0 0 (1.00000000 0.00000000) *
3) X=2,4 2 0 1 (0.00000000 1.00000000) *