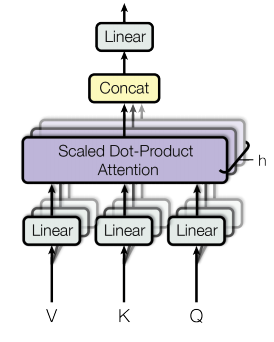
I've a conceptual question
BERT-base has a dimension of 768 for query, key and value and 12 heads (Hidden dimension=768, number of heads=12). The same is conveyed if we see the BERT-base architecture
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
Now, my question is:
Can I consider the first 64 neurons from the out_features as the first-head, the next 64 neurons from the out_features as the 2nd head and so on? (sec 3.2.2 from original paper; Link)
P.S: I referred to some of the previous posts (example), but I would appreciate any validation on this thought-process as it's similar but not same.
Update
Here's a code which prunes a particular % in particular layer depending on layer_index and prune_percentage
model = AutoModelForMaskedLM.from_pretrained(checkpoint)
linear_layers_list = []
for name, layer in model.named_modules():
if name in model_layers_list:
linear_layers_list.append(layer)
print(f"No of linear layers are: {len(linear_layers_list)}")
layer = linear_layers_list[layer_index]
if prune_type == 'ln_structured':
# Ln structured with n=1 i.e L1 pruning
prune.ln_structured(layer, name='weight', amount=prune_percentage, dim=0, n=n)
Here, I can understand that I can basically pass the Linear module and prune x% of weights.
Now, I would like to prune/remove one head in a similar fashion. Any help is appreciated!
Thanks