I am trying to understand from both a conceptual and a Python code point of view, how to represent phrases that are present in a corpus (that is used to train a neural network to classify phrases) as vectors and how to do PCA with them.
Consider that I do not want to use Word2Vec embedding and that I want only to extract the vectors from the embedding layer of my neural network.
The example I chose to understand how to do this is the following:
import numpy as np
from keras.preprocessing.text import one_hot, Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.embeddings import Embedding
# define documents
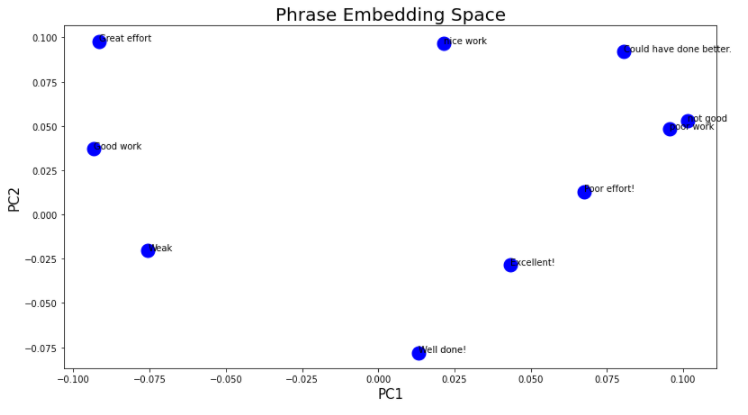
docs = np.array(['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.'])
# define class labels
labels = np.array([1,1,1,1,1,0,0,0,0,0])
# train the tokenizer
vocab_size = 15
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(docs)
encode the sentences
encoded_docs = tokenizer.texts_to_sequences(docs)
pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
define the model
model = Sequential()
model.add(Embedding(vocab_size, 2, input_length=max_length, name='embeddings'))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
fit the model
model.fit(padded_docs, labels, epochs=50, verbose=2)
It is a classifier MLP so I define the class labels corresponding to each sentence of the docs, I assign to each word an integer based on the tokenizer module, I prepare all my sequences of words to have all the same length because keras likes to work in this way, and then I finally define, compile and fit the model. After fitting the model, I can extract the weights of my embedding layer with the following line of code:
# save embeddings
embeddings = model.get_layer('embeddings').get_weights()[0]
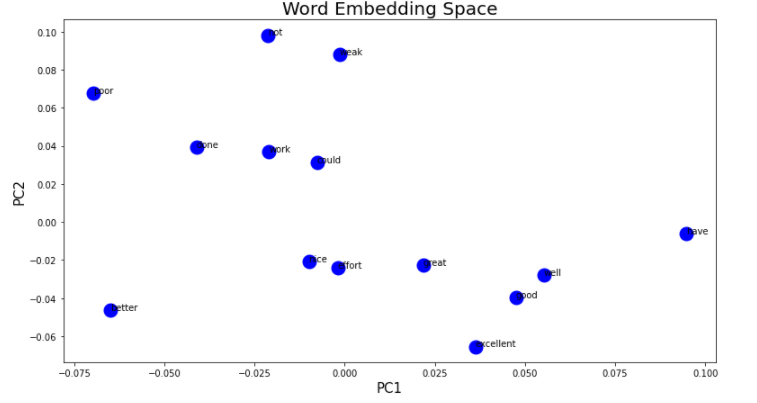
That is a 2D array with 2 dimensional embedding space (as chosen by me):
array([[-0.02900218, -0.02272025],
[-0.03750041, 0.08604637],
[ 0.00261297, 0.06689994],
[ 0.06822112, -0.07083904],
[ 0.042956 , 0.00642773],
[-0.01934443, -0.03651911],
[ 0.02451712, 0.02507548],
[ 0.01995835, 0.03889224],
[ 0.01348991, 0.01143651],
[ 0.02176871, 0.01283678],
[-0.04610137, -0.04942843],
[-0.02342983, -0.07704163],
[-0.08990634, -0.06908827],
[ 0.07353339, -0.06115208],
[-0.06146053, 0.09602208]], dtype=float32)
At this point, I have two huge difficulties:
- How to represent each phrase of the corpus with the embedding weights and so as a vector: based on the nice answer to this question, I suppose that first of all I have to check which are the integers assigned to each word and I can do it with:
print(encoded_docs)
That gives me the following representation:
[[6, 2], [3, 1], [7, 4], [8, 1], [9], [10], [5, 4], [11, 3], [5, 1], [12, 13, 2, 14]]
Then I assign to each integer the embedding weights of the trained network printed before and so I obtain:
X=np.array([[[[ 0.02451712, 0.02507548], [ 0.00261297, 0.06689994]], [[ 0.06822112, -0.07083904], [-0.03750041, 0.08604637]], [[ 0.01995835, 0.03889224], [ 0.042956 , 0.00642773]], [[ 0.01348991, 0.01143651], [-0.03750041, 0.08604637]], [ 0.02176871, 0.01283678], [-0.04610137, -0.04942843], [[-0.01934443, -0.03651911], [ 0.042956 , 0.00642773]], [[-0.02342983, -0.07704163], [ 0.06822112, -0.07083904]], [[-0.01934443, -0.03651911], [-0.03750041, 0.08604637]], [[-0.08990634, -0.06908827], [ 0.07353339, -0.06115208], [ 0.00261297, 0.06689994], [-0.06146053, 0.09602208]]]])
Is it correct to say that X contain the vector representation of all the words of my docs? Furthermore, if yes or in any case is there a function in Python that allows you to get it ? Or one should implement it from scratch? Then, I ignored the fact that the sequences were padded with zeros. Should I add zeros and make all my vectors (of the 2D array) as 4 dimensional vectors in order to represent each word properly ?
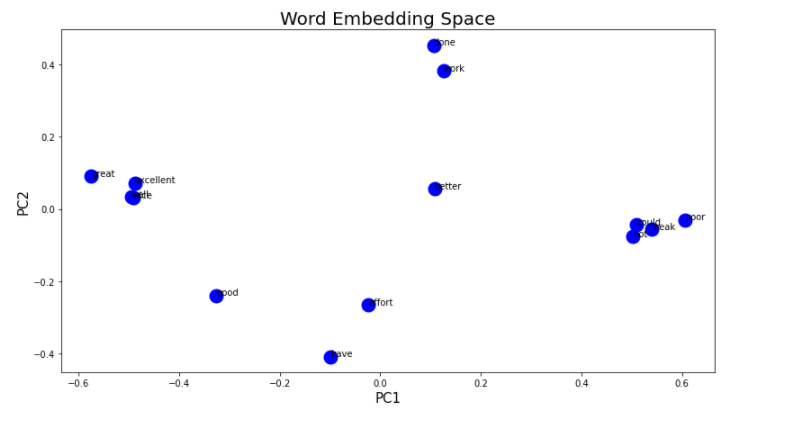
- Once I obtain my vector representation of each word in the docs, how do I do the PCA representation of the 2D array that I obtain? What are samples and what are variables? In theory, I should obtain a plot in which the data labeled as 1 cluster together and the data labeled as 0 cluster together thanks to the fact that they are now given by the weights which are obtained by training the classifier neural network.
I hope I'm not too out of the way with everything.
Thank you in advance.
P.S.: please, if you downvote the question give me the reason of your downvoting. It's not a question I threw there but there was some research effort.