(this is related to my other question, see here)
Imagine a screen, with 3 windows on it:
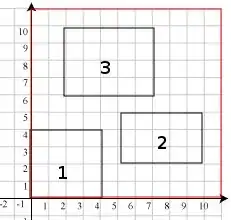
I'd like to find an efficient data structure to represent this, while supporting these actions:
- return a list of coordinates where a given window can be positioned without overlapping with others
- for the above example, if we want to insert a window of size 2x2, possible positions will be (8, 6), (8, 7), ..
- resizing a window on the screen without overlapping other windows while maintaining aspect ratio
- insert window at position x, y (assuming it doesn't overlap)
Right now my naive approach is keeping an array of windows and going over all points on the screen, checking for each one if it's in any of the windows. This is $O(n\cdot m\cdot w)$ where $n, m$ are the width, height of the screen and $w$ is the number of windows in it. Note that in general $w$ will be small (say < 10) where each window is taking a lot of space.