I came across a marketing video here. They claim to perform AES encryption and tokenization of sensitive data, at the corporate gateway, before it leaves the company firewall destined for the public cloud. So keys and token<=>plain text mapping tables remain at gateway and cipher text/tokens live in the public cloud.
The purposes of this question is to understand the real security of the product than just what is claimed. The video link is there but I've put screenshots below on the relevant portions. I did some basic analysis by simply eyeballing the video and seems the security is rather poor. You can clearly see, just from their public demo videos at the 2:19 mark, that
- all strings are dropped to lower case => tokenized
- letter casing 'flips' are then encoded (bitfield?) and appended to the token (eg "flip case of 1st character")
- the token is wrapped within pre/post ambles or delimiters
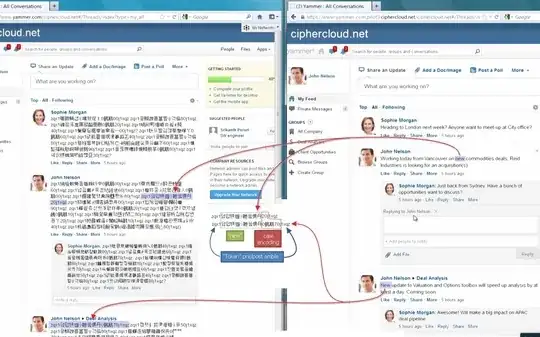
Full resolution: https://i.sstatic.net/dRnCI.jpg
{kind=link}
NOTE: Image is being referenced lawfully. Considerations include, but are not limited to, sections 107 through 118 of the copyright law, Title 17, U. S. Code. In particular, section 107 provides for lawful reproduction for the purposes of criticism, research as well as commentary.
The supposed security of such a system is that despite access to the "data in the cloud", no information is revealed. However, even without access to clear text counterparts, it should be fairly trivial to sort the "secured" tokens, drop the case encoding information, and then perform a frequency analysis and mapping it to regular English histograms. Presumably this is how they do their "search and sort, even inside encrypted data" feature.
My questions are:
- How serious do you consider such a security system?
- How many words/tokens of such "secured tokenized" data are needed to statistically decipher everything (with say, 90-95% confidence) assuming access to only tokenized data?
- Any particular reason to encode the tokens in Chinese? I would do that to visually consume the space of one character (in browsers for humans) while still encoding 2-3 bytes per UTF-8 character.
{kind=link}