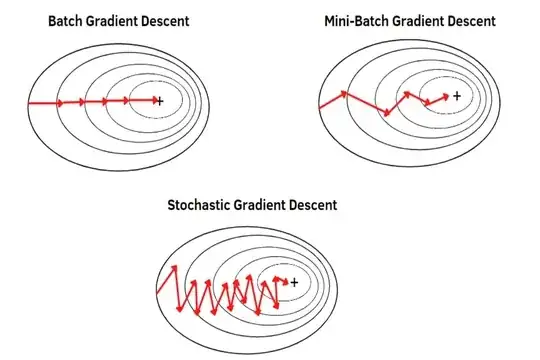
Batch Gradient Descent(BGD) uses the average of a whole dataset, so each sample is not stood out(not emphasized). As a result, the computation is stable(not fluctuated), getting an accurate value but BGD sometimes gets stuck in local minima because the computation is stable(not fluctuated) as I said before.
Mini-Batch Gradient Descent(MBGD) uses the average of each small batch splitted from a whole dataset so each sample is stood out(emphasized). *Splitting a whole dataset into smaller batches can make each sample more stood out(more emphasized). As a result, the computation is less stable(more fluctuated) than BGD, getting a less accurate value than BGD but MBGD less gets stuck in local minima than BGD because the computation is less stable(more fluctuated) than BGD as I said before.
Stochastic Gradient Descent(SGD) uses every single sample of a whole dataset one sample by one sample but not the average so each sample is more stood out(more emphasized) than MBGD. As a result, the computation is less stable(more fluctuated) than MBGD, getting a less accurate value than MBGD but SGD less gets stuck in local minima than MBGD because the computation is less stable(more fluctuated) than MBGD as I said before.
 This image is from statusneo.com.
This image is from statusneo.com.
