Practical techniques for searchable encryption proposed by Song et al. [1] have a false positive rate of $l/2^m$ where $l$ is left half of encrypted bits and $m$ is right half and $l+m=n$ where $n$ is number of bits of the word being encrypted. For getting clarity on these bits please refer the figure 3 in page 6. (paper).
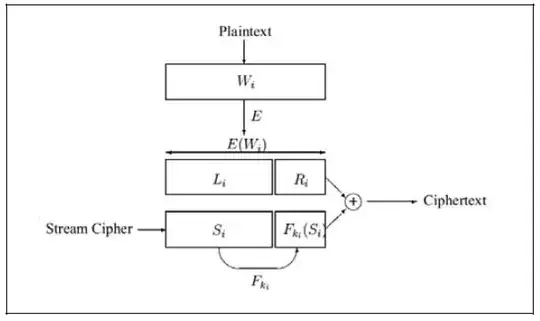 Especially when the input domain of words being encrypted is not so random say serial numbers, sequence ids etc. the false positives are simply high.
Especially when the input domain of words being encrypted is not so random say serial numbers, sequence ids etc. the false positives are simply high.
Is there any subsequent work done or techniques available for reducing the false positive rate ?
[1] – Song, Dawn Xiaoding, David Wagner, and Adrian Perrig. "Practical techniques for searches on encrypted data." Security and Privacy, 2000. S&P 2000. Proceedings. 2000 IEEE Symposium on. IEEE, 2000.